Build Your Own Internal Knowledge Search


Companies are racing to put Internal Knowledge Search tools in your hands that let your search, summarize and generate insights on your internal knowledge bases. Here is Perplexity's product announcement for internal research tool for their Enterprise Pro customers that is $40/month or $400/year a pop.
Irrespective of usecase at hand whether you are a Developer searching through tech specs written in 2000's or a Product lead performing user research on friction points through observed user journeys this will be very handy tool. If you would like to get the same done at your desk there are a gazillion approaches and perspectives that can drown you into decision fatigue but dont let that hold you back if you can spend few minutes following through the rest.
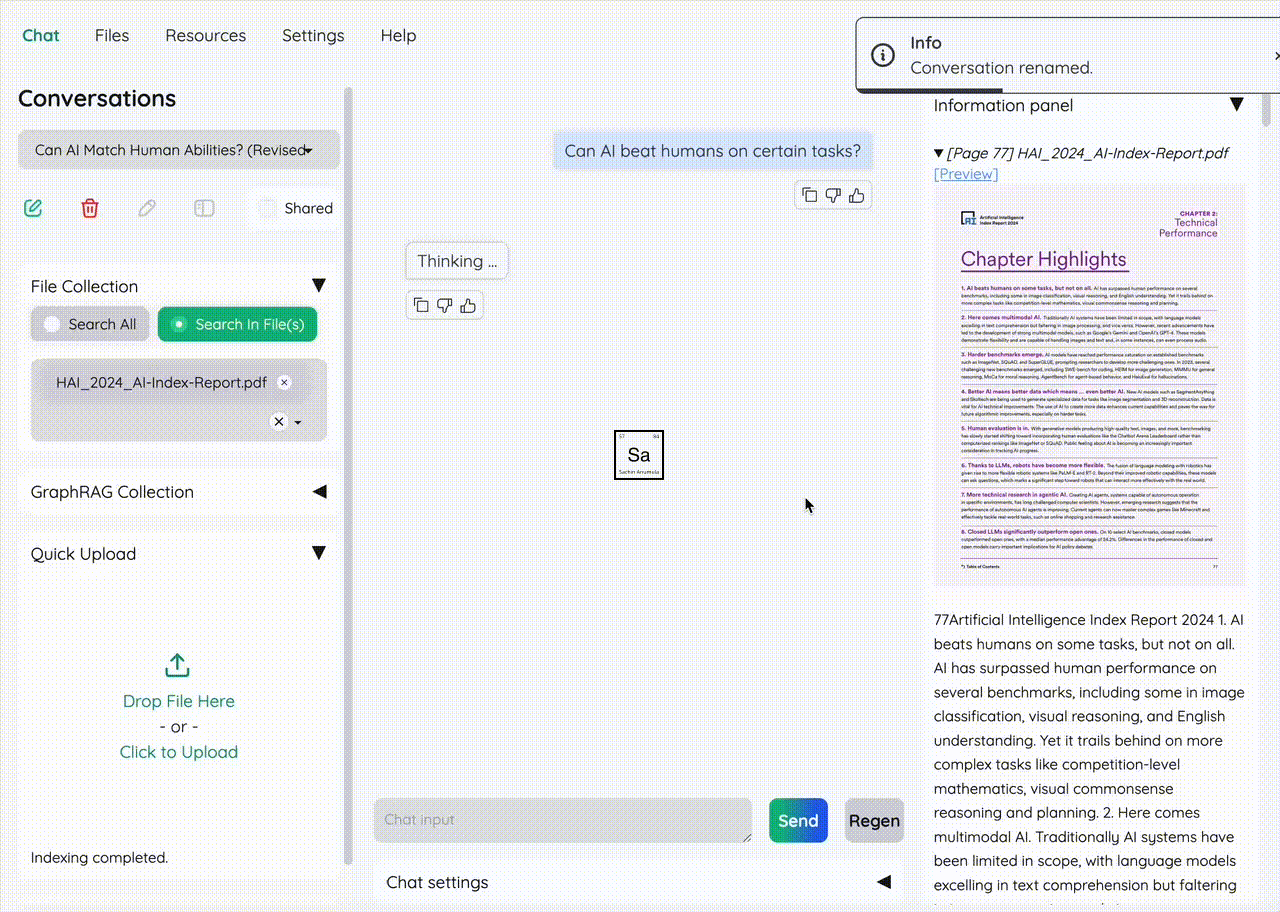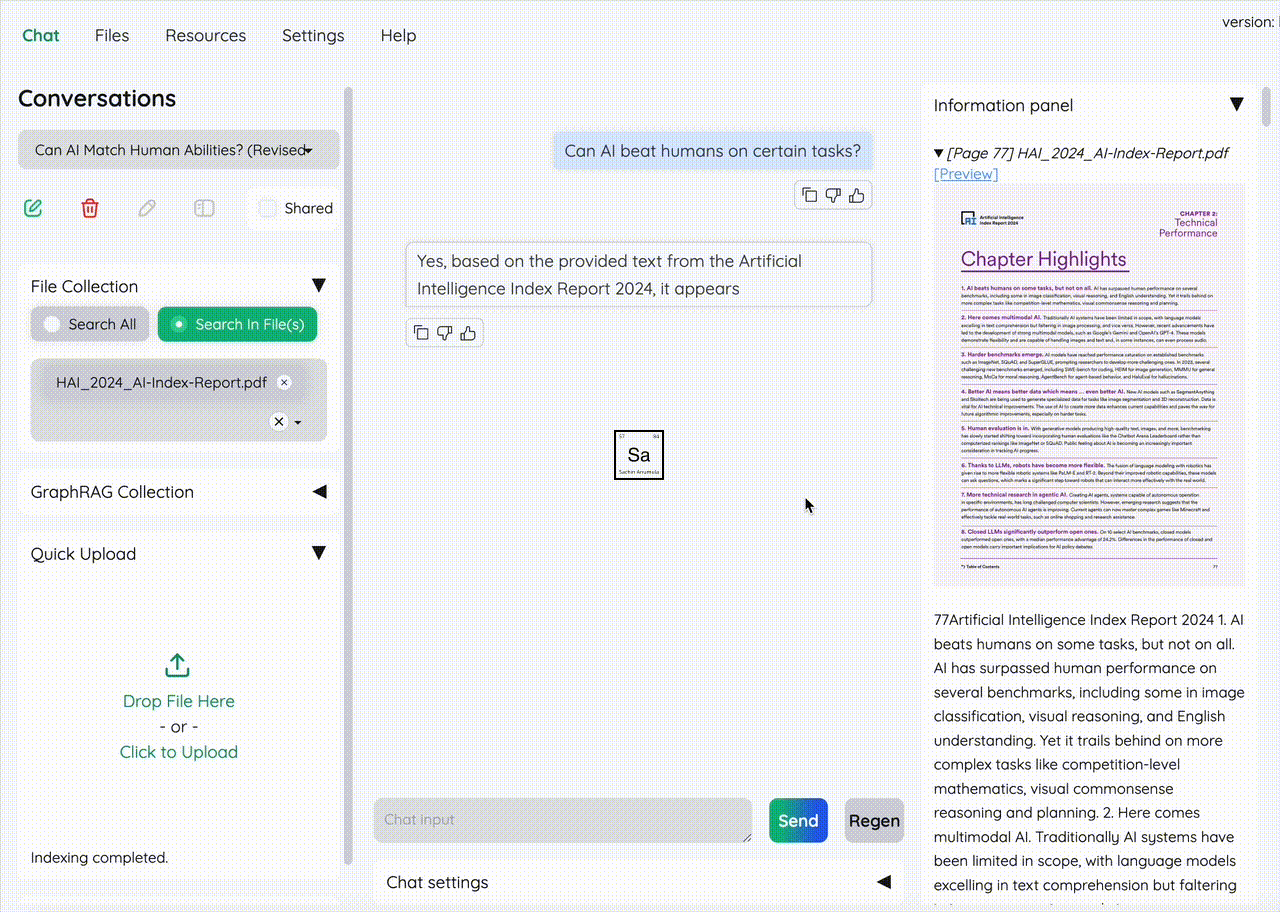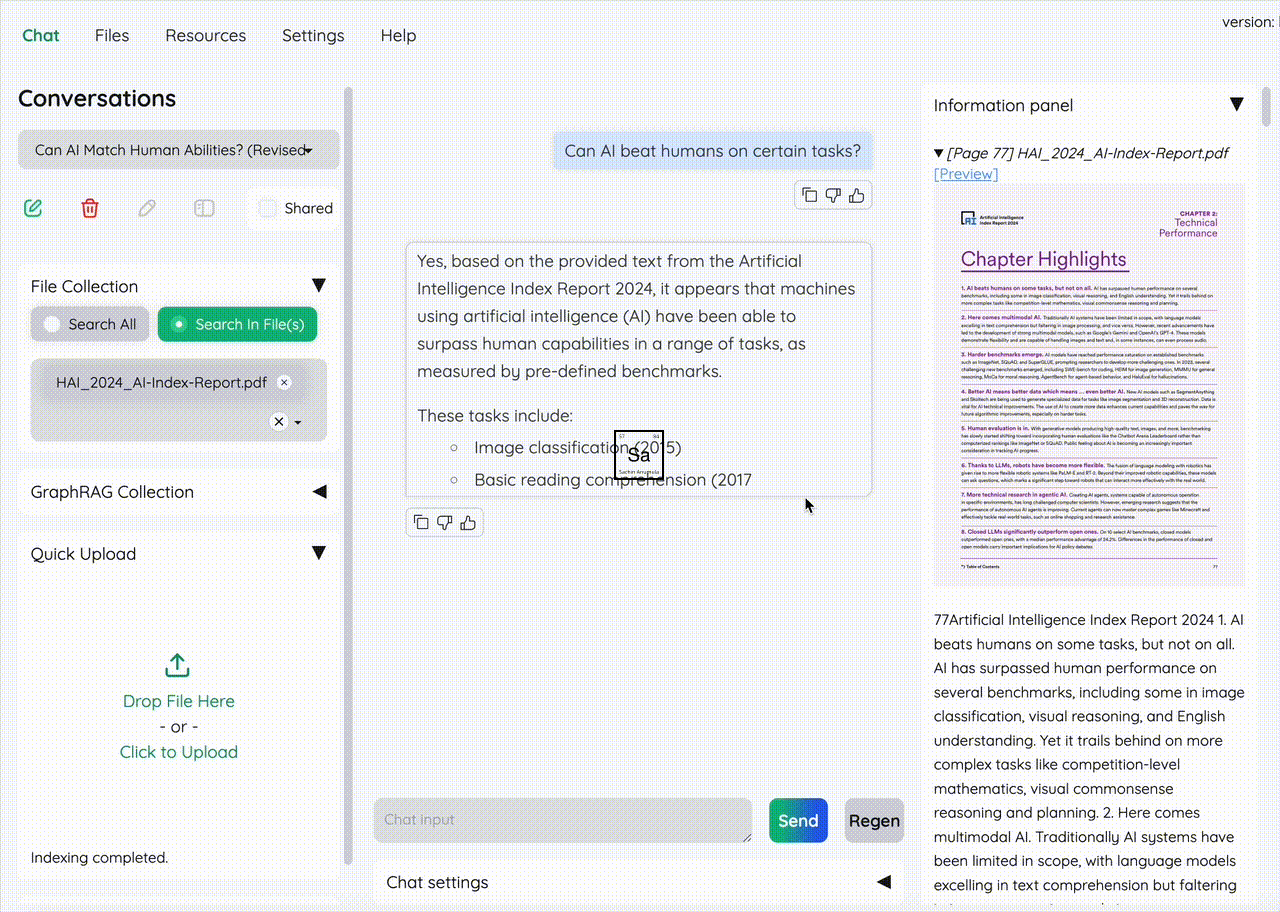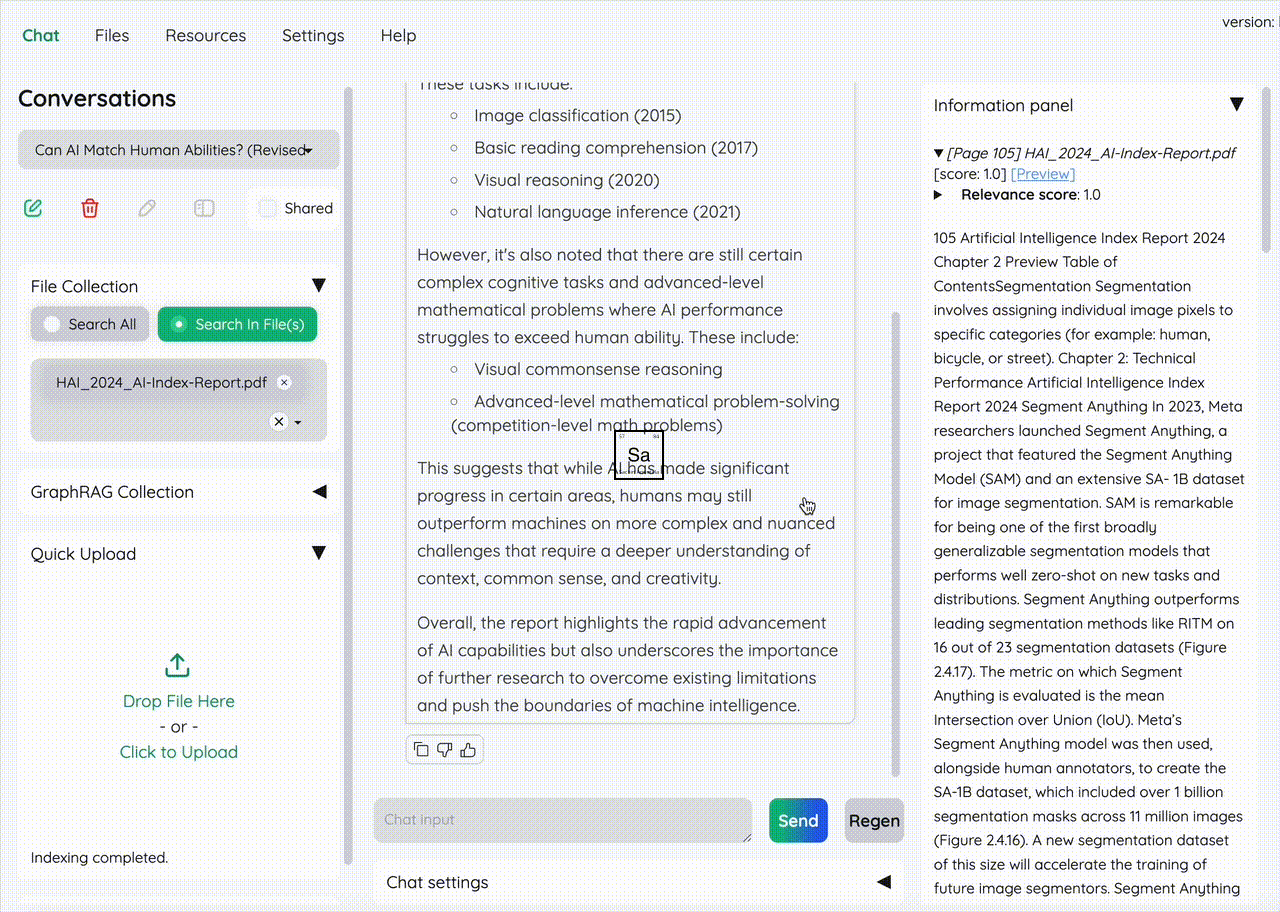
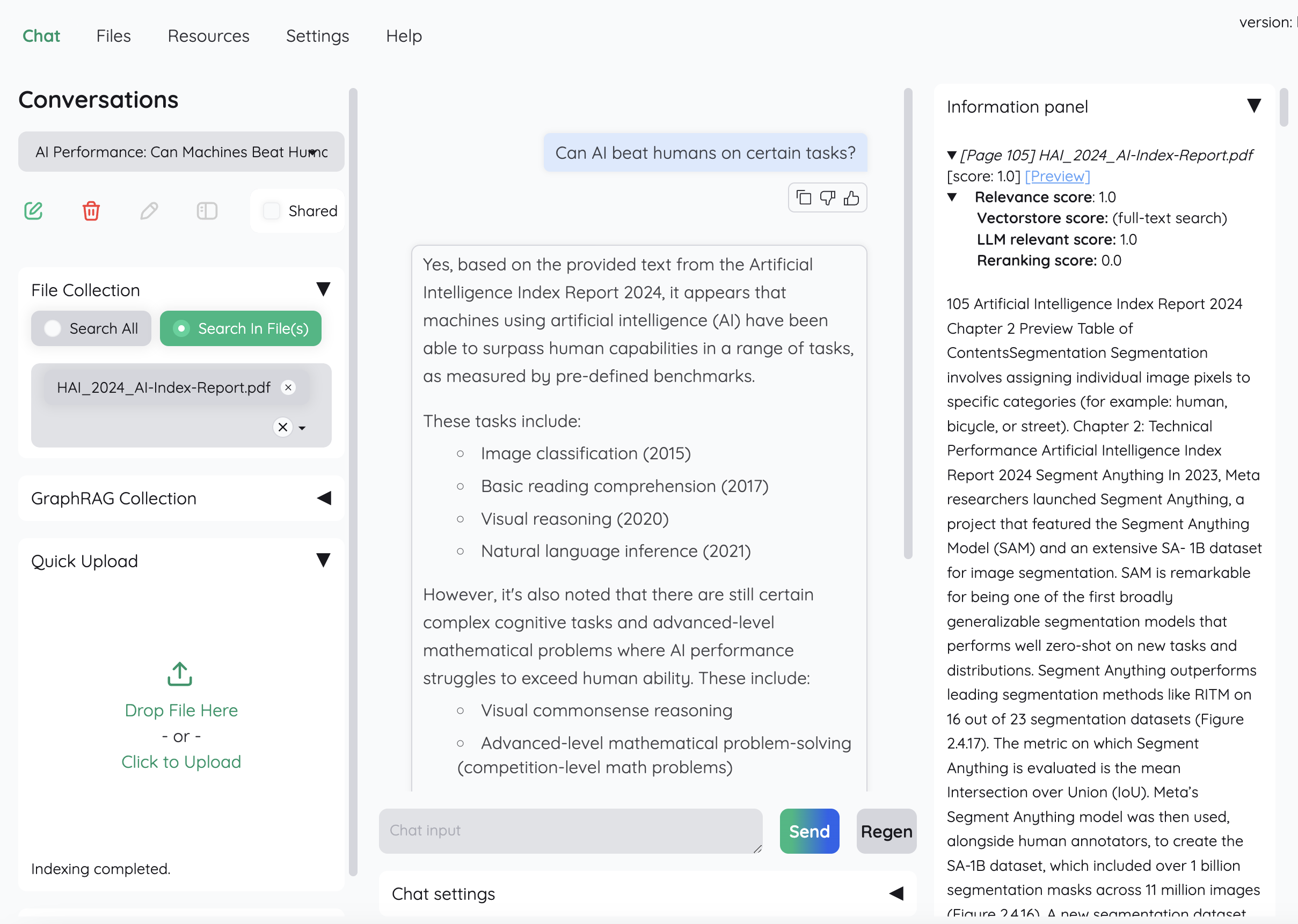 🔍 Running query on a huge AI pdf report asking it for "Can AI beat humans?"
🔍 Running query on a huge AI pdf report asking it for "Can AI beat humans?"
How do these work?
RAG - Retrieval Augmented Generation represents a shift towards more dynamic AI systems that do not just rely on pre-learned information but actively seek out relevant data to improve their performance, making AI applications more reliable, versatile, and aligned with real-time knowledge.
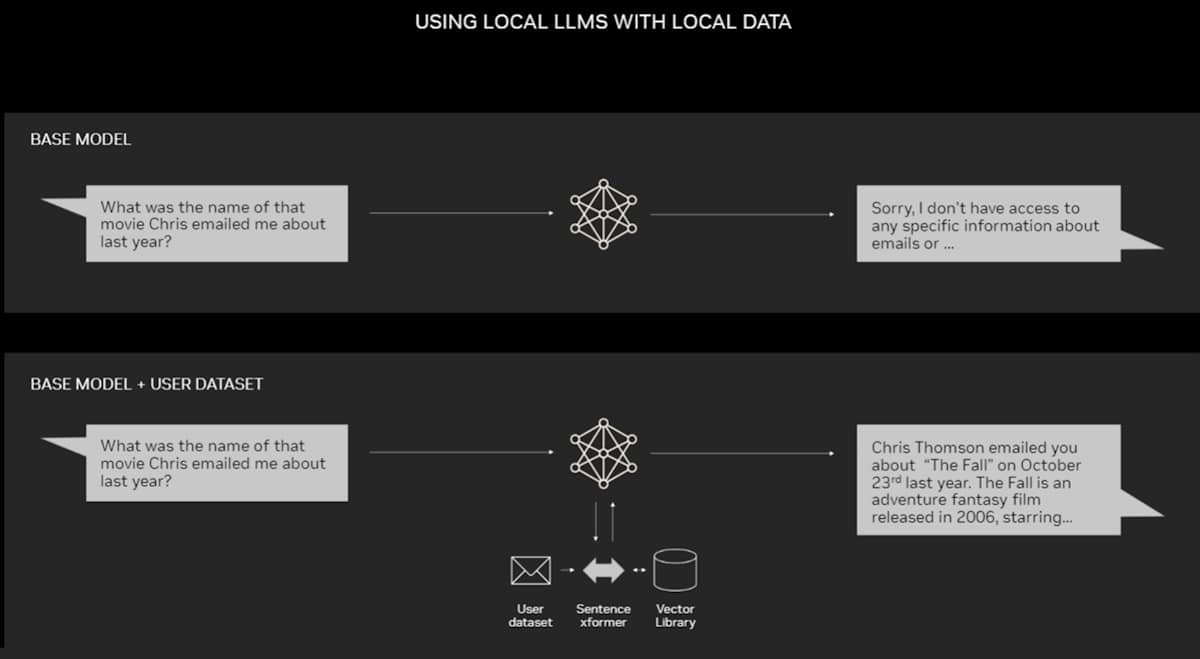 Source: NVIDIA Blog
Source: NVIDIA Blog
What you need?
- An LLM that understands your queries and generates answers with the generative process augmented with your knowledge base
- A Chat interface that lets do Question Answer sessions
Lets go assemble this together!
Picking an LLM
- Keep it simple and just grab Ollama
- Get it up and running and pull a model (suggest using
llama3.1:8bandnomic-embed-text:latest)
me@workstation:~$ ollama pull llama3.1:8b
me@workstation:~$ ollama pull nomic-embed-text
me@workstation:~$ ollama list
NAME ID SIZE MODIFIED
llama3.1:8b 42182419e950 4.7 GB 21 hours ago
nomic-embed-text:latest 0a109f422b47 274 MB 23 hours ago
me@workstation:~$ ollama show llama31:8b
Model
architecture llama
parameters 8.0B
context length 131072
embedding length 4096
quantization Q4_0
Parameters
stop "<|start_header_id|>"
stop "<|end_header_id|>"
stop "<|eot_id|>"
License
LLAMA 3.1 COMMUNITY LICENSE AGREEMENT
Llama 3.1 Version Release Date: July 23, 2024
Picking a Chat Interface
- Kotaemon, RAG UI which is as straighforward as it gets and this is how it looks live
- Recommend going the Docker route to install
docker run \
-e GRADIO_SERVER_NAME=0.0.0.0 \
-e GRADIO_SERVER_PORT=7860 \
-p 7860:7860 -it --rm \
ghcr.io/cinnamon/kotaemon:main-lite
- Jump over to
http://0.0.0.0:7860/for Setup - Setup
- Pick Local LLM
 Ignore the warning of cannot connect, just proceed and we will configure in next steps
Ignore the warning of cannot connect, just proceed and we will configure in next steps - Under Resources > LLM, configure as below
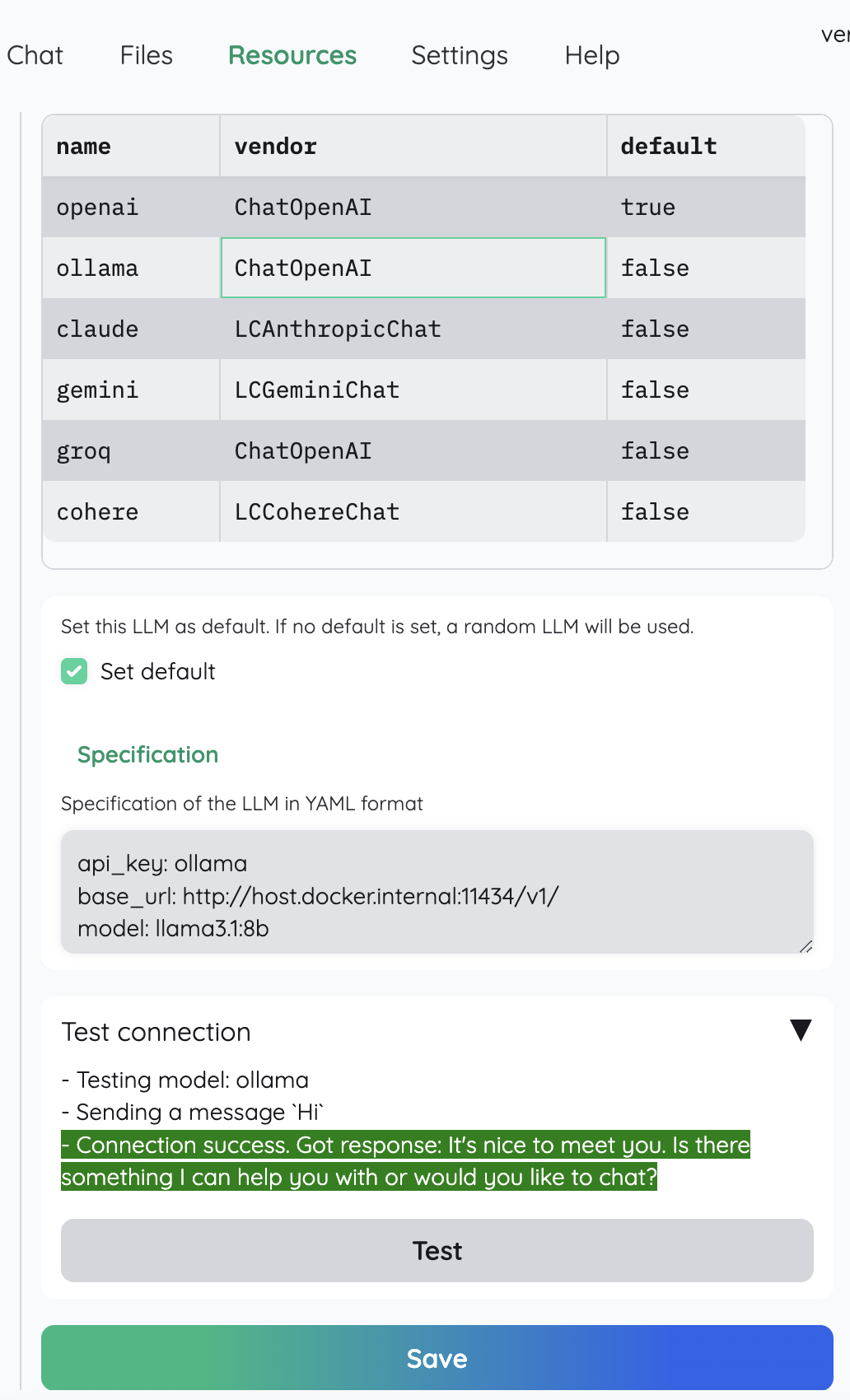
- Under Resources > Embeddings, configure as below
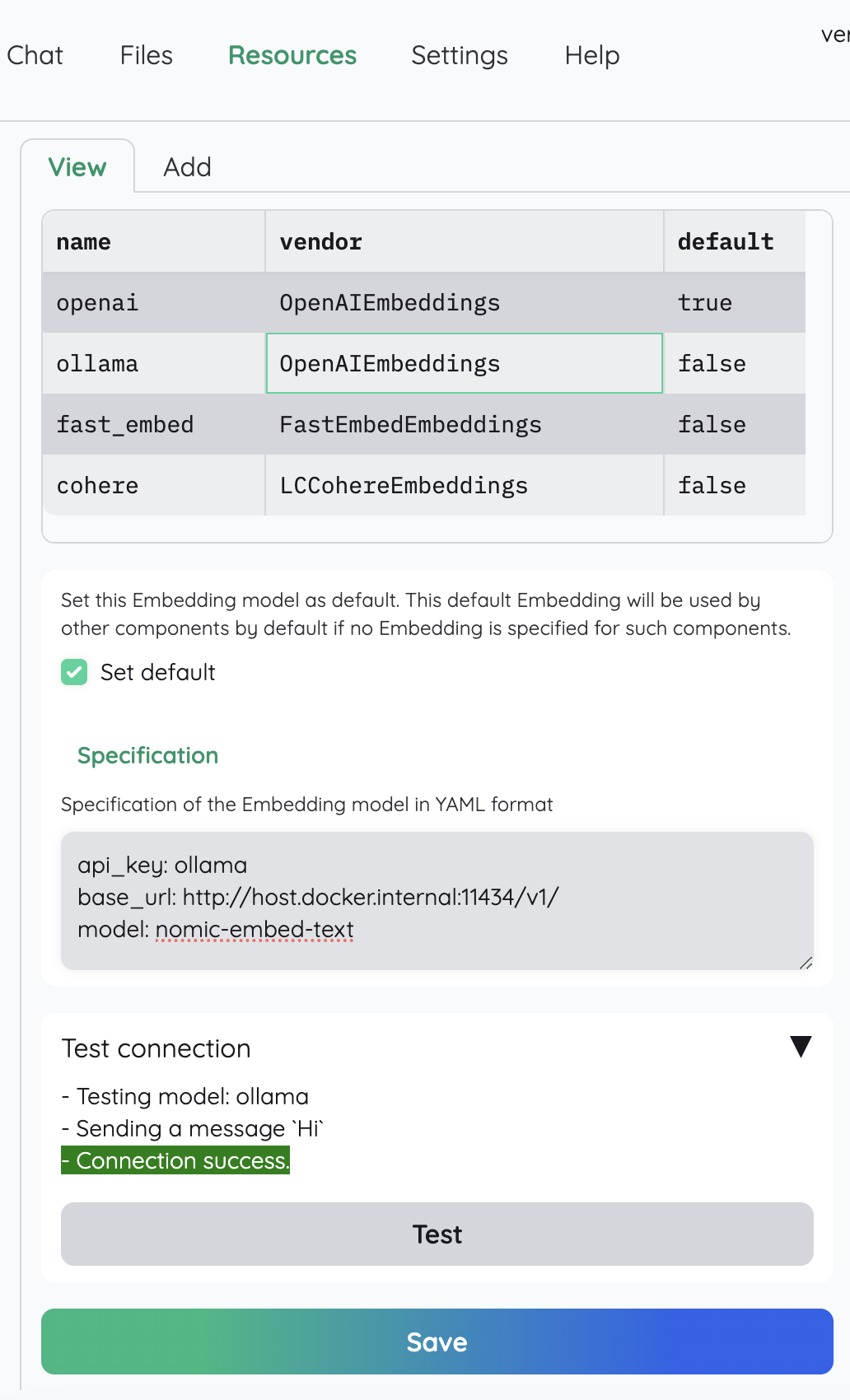
- Pick Local LLM
Use it
Upload your files and then start asking questions
That's a wrap!